
Understanding DynamoDB
Let’s try to understand DynamoDB with the help of a practical example.
Imagine that your favorite neighborhood coffee shop is blowing up, and they want an online presence. Your company got the contract, and you are tasked with designing the backend. You discuss all the requirements and try to jot down a design for the system. A database is going to be an essential part of this.
You start evaluating the database choices when DynamoDB comes to your mind. You have heard great things about it, but not really sure on the details. Well, let’s recount them.
Introduction to DynamoDB
Released in 2012, AWS defines DynamoDB as a “Fast NoSQL key-value database service for single-digit millisecond performance at any scale”.
What does this mean?!
What is DynamoDB?
It’s a noSQL database and takes a more relaxed approach towards storing data, without the restrictions and problems of a relational database.
What problems? Well, relational databases have their issues with de-normalising data, leading to storage and data integrity problems and functionalities like JOIN compromising on the speed of the query.
So instead, DynamoDB compromises on consistency for availability and speed (Recall CAP theorem).
It uses eventual consistency, which means there might be different results for the same query depending on which instance it hit.
These changes make it possible for DynamoDB to provide query latencies in single-digit milliseconds for virtually unlimited amounts of data, to the tune of 100TB+.
Why do we need it?
Let’s look at some very useful features offered by DynamoDB:
- Can store polymorphic data – structured and unstructured
- On-demand backups
- Reliable scaling without downtime or performance impact
- Easy database resource and performance monitoring via AWS console
- Fast queries and stable latencies even when the dataset grows
- Optimize storage by deleting expired items
- Convenient HTTP APIs with authz mechanisms using IAM roles – for simple and complex operations
You are convinced that DynamoDB is the right choice for your app. All the benefits we learned about just now certainly make it a competent choice for a blazing fast app.
So how would you go about the design?
Let’s start with the basics. You would definitely need tables in your db to store the data–probably a users table to store user information like name, address, DOB (to send out those birthday discount coupons, of course), and then one to store orders.
The state diagram would be something like this:
Before diving any deeper into the design, We’ll first take a look at the basic DynamoDB terminology.
Basic Operations
Terminology
Item:
Each row in a table in DynamoDB is called an item, and as it is common with databases, it has a primary key that’s used to uniquely identify each item in the table. For our app, in the users table, each user object would be an item.
Attributes:
Attributes are fields in the row or item. For example, in a users table, each item would be a row, with attributes being the username, age of the user, and their address.
Each attribute will have a type. The username most likely will be a string, phone number would be a number, and so on.
An exhaustive list of attribute types available can be found here.
An interesting thing to note is that, unlike relational databases, an item in the same table can consist of different attributes, and a table may have different kinds of items in it. This is possible due to DynamoDB’s flexible data model.
For instance, there may be users who have signed up, and we have a more comprehensive dataset on them than those who decided not to.
There is just one rule here: All the items must have an attribute that will serve as the primary key.
In fact, you can have more than one kind of item in the same table (like users and orders), as long as they have the same attribute as their primary key. This can sound very confusing to people who have worked with just relational databases, but don’t worry. Things will become more clear once we get into designing the database later.
Primary key
Primary key is an attribute that should be able to uniquely identify an item in a table. These are per table and need to be specified at the time of table creation.
It also serves another purpose–the items in a table are indexed on the primary keys, making them the most efficient way to query a table.
A simple primary key is also called the partition or the HASH key, since it is used to determine the shard in which the item will be stored.
Simple primary key? Is there any other kind? Yes, there is, and we’ll learn more about the complexities of primary keys in later sections. An item collection in DynamoDB refers to all the items in a table or index that share a partition key.
How to create a NoSQL table?
Let’s proceed with designing our database. Ideally, we would want users to visit our website and sign up in order to place their orders.
Let’s create a users table for it. The main things we’ll need are:
- Table name
- Attribute definition: This includes specifying attribute type and its value. We’ll add attributes Username, Age, and Address, with Username as the primary key (or hash key).
- Provisioned Throughput: It represents the read and write capacity of the table. With other databases, we usually choose an instance size for the db based on our storage, CPU and RAM requirements. But with DynamoDB, the provisioning is done only by read and write operation units per second.
This is what the create query would look like in AWS CLI:

Add data to the table and query it
As mentioned earlier, DynamoDB has a handy set of APIs that can be used to query the table and perform operations on it. The most common ones are:
- To insert an item:
- Use the PutItem API
- This API will completely overwrite any existing item in the table.
- To avoid inserting if an item with the same primary key already exists, use
--condition-expressionwithattribute_not_exists.

Expression-attribute-namesis an expression used to specify placeholders for attribute names, like for variable user1. You may need these if your attribute name conflicts with DynamoDB’s reserved keywords.- To retrieve item:
- Use the GetItem API.
- This would use the primary key and can be used to retrieve the entire row or just a few attributes. The result will be in the key “Item”.

Response:

- To retrieve just some of the attributes from the item, use the
projection-expression. This flag can also be used to retrieve nested fields, in case the attribute is a list or a map. - The
keyexpression used we see above can only be used on the primary keys. - To update an item:
- Set: To add a new attribute to an item or update an existing one
- Add: Used to increment/decrement a Number or insert elements into a Set.
- Remove: To remove an attribute from a set/.
- Use UpdateItem with the update-expression flag.
- This flag may be the following clauses:
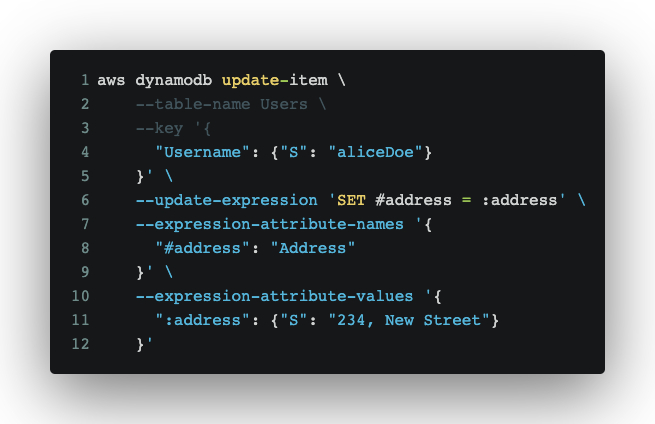
- Delete item
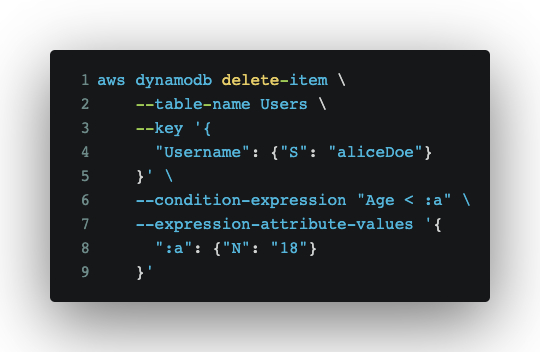
- Use DeleteItem to remove an entire item from the table.
- DELETE: Used to remove items using a primary key
- Similar to the PutItem call, you can add a
--condition-expressionto only delete your item under certain conditions.
- Batch Write: As the name suggests, it is used to insert a batch of items into the table. This API returns a key
UnprocessedItems, which will have details of the items whose insertion failed due to some errors, like throttling. You can read about it in detail here. - Scan:
- The scan call is a blunt tool to get all the items in the table. Unlike the GetItem API, it doesn’t need a primary key.
- Since it doesn’t use a primary key, there is no indexing, which makes it a very resource-heavy operation. Hence, it should not be used lightly.
- The responses are paginated and you will get only 1 MB of response before the pagination happens. You can learn more about it here.
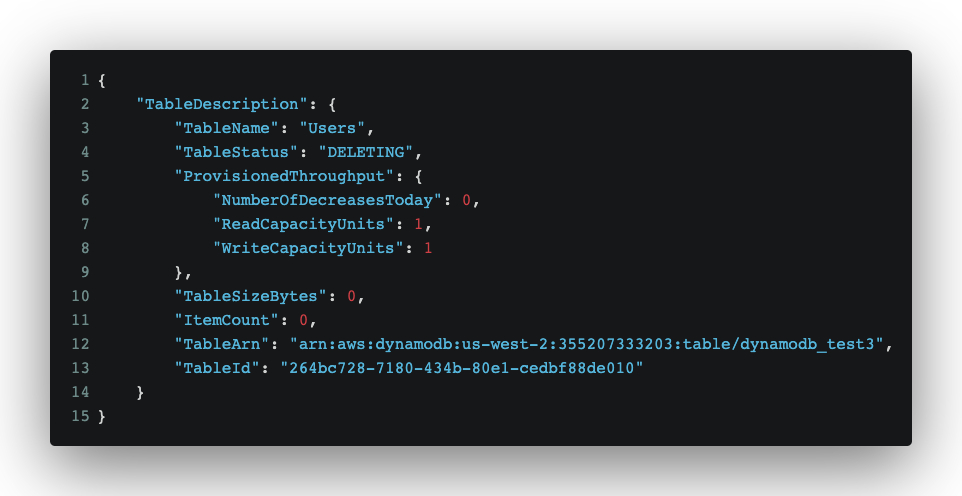
Delete the table
- A table can be deleted by using the DeleteTable API.

Response:
After the insertion discussion above, the users table would now look something like this:
Primary Key Attributes
| UserName | Name | Age | Address |
| aliceDoe | Alice Doe | 25 | 123, Good Street |
So far, we have seen quite a few handy API to help set up our database, but the query patterns in the real world are usually more complex than just getting a few items under certain conditions on the primary key.
Let’s see how that can be handled in DynamoDB.
How to use keys and indexes for effective querying
Now we have a users table to store the information of the customers, but to enable the business to be successful, the customers need to place orders. We’ll put that information in another table called Orders, but before that, we’ll need to decide on a primary key. We need to specify them at the time of table creation, remember?
The Orders table can have information like orderid, cost of the order, user id, timestamp when the order was placed, etc.
We have just gone through a very handy set of APIs to help set up these tables.
But can they help with the real-world access patterns, like:
- Get a user and all the orders of their order
- Get all the orders for a user that has an amount > x
- Get all the orders above a certain amount on a particular day
Querying this data certainly doesn’t seem possible with the primary key alone–but is it? Let’s discuss this a bit more by diving deeper into primary keys.
How to choose the primary key
As we have already learned, primary keys are an attribute in a table that are unique to a row, or as say in DynamoDB, an item.
Let’s think about our design for a second. Do we really need a separate table for orders? Moreover, DynamoDB does not support foreign keys or joins. Wouldn’t it be better if we just stored the order information in the users table itself as a UserOrder table? What would be the primary key of such a table? We can’t use just userid anymore. How about a combination of user and order id?
This is where composite primary keys come into the picture.
Along with regular single-attribute primary keys, we have something called composite primary keys.
Let’s take a look at what they are.
Composite keys:
A composite primary key consists of two attributes: partition/hash key + range/sort key.
The second attribute, range key, is used to order items within the same hash key. There is a 1:many relationship between the hash and range keys.
Since composite keys are primary, a combination of hash + sort key is always unique in a table.
The main advantage of composite keys is that they allow for more complex query patterns, as opposed to the simple get and put operation that can be done with a simple primary key.
We’ll create a UserOrders table:
- With a composite primary key
- The same user item we did before with the primary key being Username + PROFILE
- An Order item, with a creation date and the amount of order, with the primary key being Username + OrderID
- Here, PROFILE is just a string that we are using as a sort key. It’s common to use a filler like this in DynamoDB, especially in a polymorphous table, since a User item won’t have an orderID here.
So now we can query for all orders of a user using the username as key and it will return the both the user information and all of their order, as follows:
| Partition Key – Username | Sort Key | Age | Address | CreationDate | Amount |
| aliceDoe | PROFILE | 21 | 123, Good Street | ||
| aliceDoe | ORDER#54312 | 2022-02-02 | 15 |
Composite keys are cool, but they still don’t help the second and third access patterns.
Advanced querying and filtering on the tables based in indexing filtering
Just like projection and conditions, filter is another type of expression in DynamoDB. It is used when we want to filter on attributes other than the primary key.
We’ll add a few more items (well, just one here) in the table so it looks like this:
| Partition Key | Sort Key | Age | Address | CreationDate | Amount |
| aliceDoe | PROFILE | 25 | 123, Good Street | ||
| aliceDoe | ORDER#54312 | 2022-02-02 | 15 | ||
| aliceDoe | ORDER#54333 | 2022-02-03 | 10 |
If we want to find out all the orders placed by a user after 2022-02-02 (the second access pattern), the query would be:

Response:

What are these scanned counts in response?
Filters will retrieve all items specified by the query and then apply the filters. We get the result we want, but the read capacity being consumed is of the total elements being read from the db. It’s convenient, but not very efficient.
Is there a better way? Let’s find out.
Indexing: LSI and GSI
DynamoDB has something called secondary indexes, and they allow you to specify alternate key structures, which can be used in Query or Scan operations (but not GetItem operations). There are 2 types:
| Parameter | LSI | GSI |
| Name | Local Secondary Index | Global Secondary Index |
| PK | Used when PK is composite | Used when PK is simple or composite |
| Creation Time | Must be added at table creation | Added after table creation(?) |
| Attribute restrictions | LSI sort key is not a mandatory attribute | GSI attributes are not mandatory in an item |
| Uniqueness | Unique | Need not be unique |
| Read/write capacity | Read and write capacity is counted in table’s base capacity | Read/write capacity is in addition to the base table’s capacity |
| Size limitations | 10GB limit per hash key | No storage limit(?) |
| No. of key limitation | 5 LSI per table | 20 GSI per table |
| Consistency | Configurable: Both Strong and eventual consistency supported | Only eventual consistency supported* |
* This means you may get different results when querying a table and a global secondary index at the same time.
Local Secondary Index(?)
For our UsersOrders table, we’ll define an LSI called UsernameCreationDate with the same partition key as the primary key + a different sort key.
UsernameCreationDate-index = Username(Partition key) + CreationDate(Sort key)
Access pattern: Get all orders of a user after the date 2022-02-02.
| Partition Key | Sort Key | Age | Address | LSI Sort Key CreationDate | Amount |
| aliceDoe | PROFILE | 25 | 123, Good Street | ||
| aliceDoe | ORDER#54312 | 2022-02-02 | 15 | ||
| aliceDoe | ORDER#54333 | 2022-02-03 | 10 |

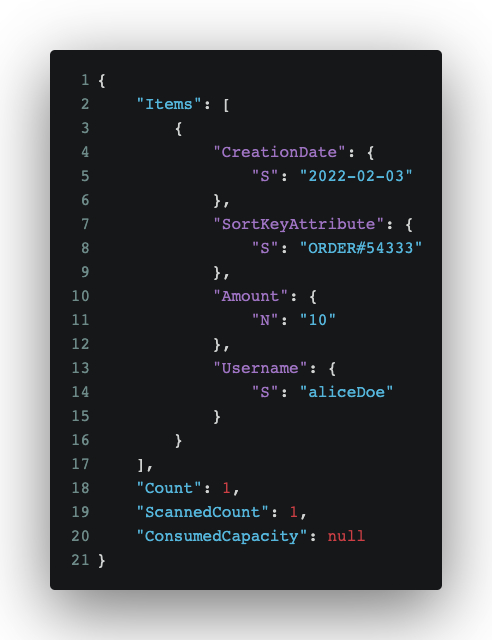
Notice the scanned count here is 1 instead of 3 (which was with filter expression earlier.) This is the power of indexing!
Global Secondary Index
The last access pattern, “Get all the orders above a certain amount on a particular day” can be solved if we use GSI instead of LSI.
Let’s define it, with both the partition and the sort key being different from that of the primary key.
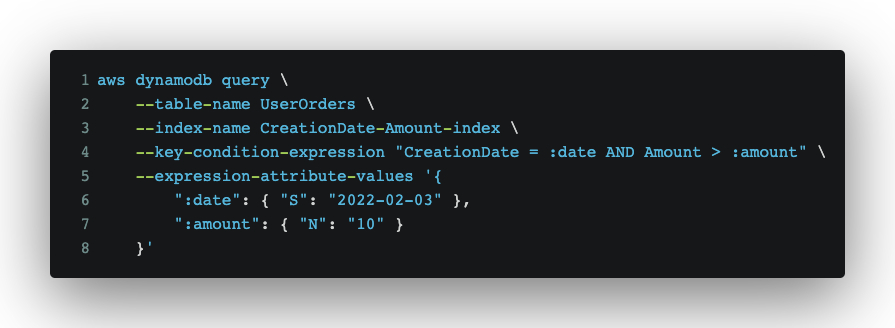
CreationDate-Amount-index = CreationDate(Partition key) + Amount(Sort key)
The table would look like (we also inserted another user item and order item):
| Partition Key | Sort Key | Age | Address | GSI Partition Key(CreationDate) | GSI Sort Key(Amount) |
| aliceDoe | PROFILE | 25 | 123, Good Street | DATE | |
| aliceDoe | ORDER#54312 | 2022-02-02 | 15 | ||
| aliceDoe | ORDER#54333 | 2022-02-03 | 10 | ||
| johnWilliam | PROFILE | 21 | 234, MyStreet | DATE | |
| johnWilliam | ORDER#54345 | 2022-02-03 | 25 |
The partition key in a GSI is a mandatory field, so we are using a placeholder string “DATE” in field CreationDate for User items.
Just like primary key, the GSI in partition key should be a high cardinality attribute.
Note that only equality expressions are allowed on the partition key.
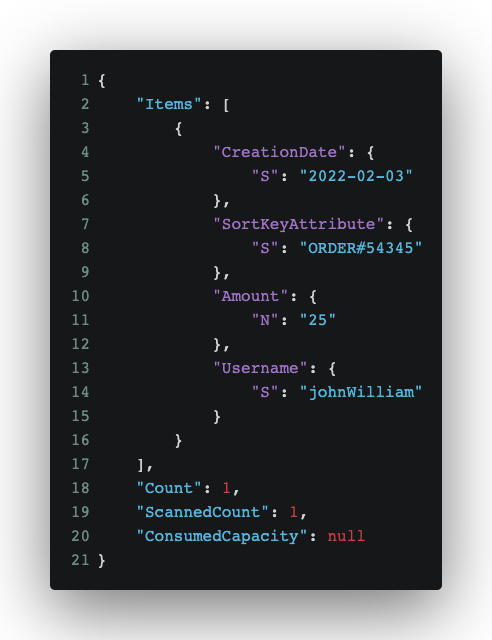
Querying “Get all order placed on date 2022-02-03 above a certain amount”:
Note that including an attribute in LSI or GSI is known as projecting that attribute into the index, and it shouldn’t be taken lightly. You can read more here.
Best practices
Let’s summarize some of the things we have just read about:
- Finalize the access patterns before designing the database.
- Choose a high cardinality attribute for the primary key to distribute the load evenly across shards.
- Never use scan calls, unless you know what you are doing.
- Use indexes wherever possible, but don’t over-use them. Always keep in mind the read and write capacity they may utilize.
- As shown above, combining the orders and users item into a single UserOrders table is called a Single Table Design Pattern. Use it wherever possible, but don’t force it.
What we have learned so far is a good introduction, but DynamoDB offers so much more. Here are a few topics I recommend you look into:
- DynamoDB streams
- Patterns: Write-sharding, Scatter-Gather
- Single table design
- AWS re:invent talk 2019
- GraphQL and DynamoDB
References:
- https://docs.aws.amazon.com/amazondynamodb/latest/developerguide/Introduction.html
- https://www.dynamodbguide.com/what-is-dynamo-db/
Check out Sangeeta’s profile on Gun.io to learn more about her work, and check out our site to find out how you can hire the best minds in engineering.



